Scraping financial data from finviz with R and rvest package
<!–
–>
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
pre > code.sourceCode { white-space: pre; position: relative; }
pre > code.sourceCode > span { display: inline-block; line-height: 1.25; }
pre > code.sourceCode > span:empty { height: 1.2em; }
.sourceCode { overflow: visible; }
code.sourceCode > span { color: inherit; text-decoration: inherit; }
div.sourceCode { margin: 1em 0; }
pre.sourceCode { margin: 0; }
@media screen {
div.sourceCode { overflow: auto; }
}
@media print {
pre > code.sourceCode { white-space: pre-wrap; }
pre > code.sourceCode > span { text-indent: -5em; padding-left: 5em; }
}
pre.numberSource code
{ counter-reset: source-line 0; }
pre.numberSource code > span
{ position: relative; left: -4em; counter-increment: source-line; }
pre.numberSource code > span > a:first-child::before
{ content: counter(source-line);
position: relative; left: -1em; text-align: right; vertical-align: baseline;
border: none; display: inline-block;
-webkit-touch-callout: none; -webkit-user-select: none;
-khtml-user-select: none; -moz-user-select: none;
-ms-user-select: none; user-select: none;
padding: 0 4px; width: 4em;
color: #aaaaaa;
}
pre.numberSource { margin-left: 3em; border-left: 1px solid #aaaaaa; padding-left: 4px; }
div.sourceCode
{ background-color: #f8f8f8; }
@media screen {
pre > code.sourceCode > span > a:first-child::before { text-decoration: underline; }
}
code span.al { color: #ef2929; } /* Alert */
code span.an { color: #8f5902; font-weight: bold; font-style: italic; } /* Annotation */
code span.at { color: #204a87; } /* Attribute */
code span.bn { color: #0000cf; } /* BaseN */
code span.cf { color: #204a87; font-weight: bold; } /* ControlFlow */
code span.ch { color: #4e9a06; } /* Char */
code span.cn { color: #8f5902; } /* Constant */
code span.co { color: #8f5902; font-style: italic; } /* Comment */
code span.cv { color: #8f5902; font-weight: bold; font-style: italic; } /* CommentVar */
code span.do { color: #8f5902; font-weight: bold; font-style: italic; } /* Documentation */
code span.dt { color: #204a87; } /* DataType */
code span.dv { color: #0000cf; } /* DecVal */
code span.er { color: #a40000; font-weight: bold; } /* Error */
code span.ex { } /* Extension */
code span.fl { color: #0000cf; } /* Float */
code span.fu { color: #204a87; font-weight: bold; } /* Function */
code span.im { } /* Import */
code span.in { color: #8f5902; font-weight: bold; font-style: italic; } /* Information */
code span.kw { color: #204a87; font-weight: bold; } /* Keyword */
code span.op { color: #ce5c00; font-weight: bold; } /* Operator */
code span.ot { color: #8f5902; } /* Other */
code span.pp { color: #8f5902; font-style: italic; } /* Preprocessor */
code span.sc { color: #ce5c00; font-weight: bold; } /* SpecialChar */
code span.ss { color: #4e9a06; } /* SpecialString */
code span.st { color: #4e9a06; } /* String */
code span.va { color: #000000; } /* Variable */
code span.vs { color: #4e9a06; } /* VerbatimString */
code span.wa { color: #8f5902; font-weight: bold; font-style: italic; } /* Warning */

Introduction
If you’re an active trader or investor, you’re probably aware of the importance of keeping up with the latest stock market news and trends. One tool that many traders use to stay on top of market movements is Finviz, a popular financial visualization website that offers a range of powerful tools and data visualizations to help traders make informed investment decisions.
While Finviz is a valuable resource for traders, manually collecting and analyzing data from the website can be time-consuming and inefficient. But this is a data science blog, right? Let’s build a scraper to make our life easier! With this simple function I’m about to show, you will be able to extract the data from the website and analyze it in a streamlined way.
Disclaimer
Before diving into the topic, it’s important to note that web scraping can potentially violate website terms of service and can even be illegal in some cases. Let’s be polite and don’t use this code to resell any information, as this is not permitted by their terms of use. For educational and personal purposes only.
Into the water
To build this simple scraper we are going to use the rvest package. R developers are quite funny, aren’t they?
First thing is to get the full html we will parse later.
symbol <- "MSFT"
finviz_url <- glue::glue("https://finviz.com/quote.ashx?t={symbol}")
finviz_html <- tryCatch(rvest::read_html(finviz_url), error=function(e) NULL)
This is what the website look like after searching for a ticker.

We want to focus mainly on the table at the bottom which contains a ton of information for the company, including relevant data such as market capitalization, P/E, insider and institutional ownership or short interest.
Also, it’s nice to have our companies organized by sector and industry, as this information is also relevant for potential analysis.
Let’s get this small piece of information first, which sits right below the chart, in the middle of the page:
sector_str % rvest::html_element(xpath = '/html/body/div[4]/div/table[1]') %>% rvest::html_table() %>% head(1) %>% pull(X4) sector_str ## [1] "Technology | Software - Infrastructure | USA"
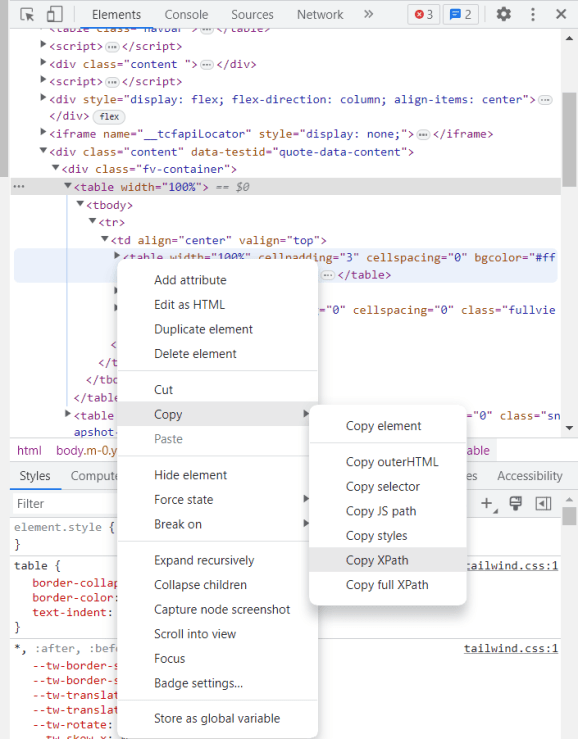
Finding the path to the specific element we are looking for is as easy as stepping into developing mode in the web browser (F12) and find your way to the element within the html code. Right-click and copy XPath as shown in the image below:

It’s easy to notice that the information we got above it’s all stored as a character of length one. This is typically undesirable as they represent different variables.
We can clean it easily with some text engineering. Tidyverse saves the day again:
sector_df %
str_split("[|]", simplify = T) %>%
str_squish() %>%
as_tibble() %>%
mutate(variable = c("sector", "industry", "country")) %>%
relocate(variable) %>%
add_row(variable = "ticker", value = symbol, .before = 1)
sector_df
## # A tibble: 4 × 2
## variable value
##
## 1 ticker MSFT
## 2 sector Technology
## 3 industry Software - Infrastructure
## 4 country USA
Much better.
We will scrape now the main table:
raw_tbl % rvest::html_element(xpath = '/html/body/div[4]/div/table[2]') %>% rvest::html_table()
However, in this case variables and values are totally mixed up in the table:
raw_tbl ## # A tibble: 12 × 12 ## X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 ## ## 1 Index DJIA,… P/E 28.99 EPS … 8.99 Insi… 0.06% Shs … 7.45B Perf… 2.61% ## 2 Market Cap 1970.… Forw… 24.27 EPS … 10.75 Insi… -0.7… Shs … 7.44B Perf… -0.8… ## 3 Income 67.45B PEG 2.42 EPS … 2.23 Inst… 72.4… Shor… 0.46… Perf… 6.26% ## 4 Sales 204.0… P/S 9.65 EPS … 19.8… Inst… 0.46% Shor… 34.3… Perf… -2.2… ## 5 Book/sh 24.58 P/B 10.61 EPS … 14.8… ROA 18.8… Targ… 285.… Perf… -6.8… ## 6 Cash/sh 13.17 P/C 19.80 EPS … 12.0… ROE 39.3… 52W … 213.… Perf… 8.74% ## 7 Dividend 2.72 P/FCF 48.47 EPS … 24.3… ROI 31.3… 52W … -17.… Beta 0.91 ## 8 Dividend % 1.04% Quic… 1.90 Sale… 15.5… Gros… 68.2… 52W … 22.1… ATR 6.40 ## 9 Employees 221000 Curr… 1.90 Sale… 2.00% Oper… 40.5… RSI … 57.55 Vola… 2.75… ## 10 Optionable Yes Debt… 0.35 EPS … -11.… Prof… 33.0… Rel … 1.07 Prev… 253.… ## 11 Shortable Yes LT D… 0.32 Earn… Jan … Payo… 28.1… Avg … 31.2… Price 260.… ## 12 Recom 1.90 SMA20 2.01% SMA50 4.88% SMA2… 3.30% Volu… 33,6… Chan… 2.71%
We can extract headers and values with the following chunk of code:
# flatten_chr will collapse all columns into one vector headers % select(seq(1,11,2)) %>% flatten_chr() values % select(seq(2,12,2)) %>% flatten_chr()
This is what the header vector looks like now:
headers ## [1] "Index" "Market Cap" "Income" ## [4] "Sales" "Book/sh" "Cash/sh" ## [7] "Dividend" "Dividend %" "Employees" ## [10] "Optionable" "Shortable" "Recom" ## [13] "P/E" "Forward P/E" "PEG" ## [16] "P/S" "P/B" "P/C" ## [19] "P/FCF" "Quick Ratio" "Current Ratio" ## [22] "Debt/Eq" "LT Debt/Eq" "SMA20" ## [25] "EPS (ttm)" "EPS next Y" "EPS next Q" ## [28] "EPS this Y" "EPS next Y" "EPS next 5Y" ## [31] "EPS past 5Y" "Sales past 5Y" "Sales Q/Q" ## [34] "EPS Q/Q" "Earnings" "SMA50" ## [37] "Insider Own" "Insider Trans" "Inst Own" ## [40] "Inst Trans" "ROA" "ROE" ## [43] "ROI" "Gross Margin" "Oper. Margin" ## [46] "Profit Margin" "Payout" "SMA200" ## [49] "Shs Outstand" "Shs Float" "Short Float / Ratio" ## [52] "Short Interest" "Target Price" "52W Range" ## [55] "52W High" "52W Low" "RSI (14)" ## [58] "Rel Volume" "Avg Volume" "Volume" ## [61] "Perf Week" "Perf Month" "Perf Quarter" ## [64] "Perf Half Y" "Perf Year" "Perf YTD" ## [67] "Beta" "ATR" "Volatility" ## [70] "Prev Close" "Price" "Change"
Perfect! Finally pasting all the info together, we get this fine data frame containing all the information:
finviz_df % bind_cols(variable = headers, .) %>% bind_rows(sector_df, .) finviz_df ## # A tibble: 76 × 2 ## variable value ## ## 1 ticker MSFT ## 2 sector Technology ## 3 industry Software - Infrastructure ## 4 country USA ## 5 Index DJIA, NDX, S&P 500 ## 6 Market Cap 1970.40B ## 7 Income 67.45B ## 8 Sales 204.09B ## 9 Book/sh 24.58 ## 10 Cash/sh 13.17 ## # … with 66 more rows
Function to take away
We can easily assemble a function joining all these pieces together. Ready to rumble:
Get_finviz_data <- function(symbol){
Sys.sleep(1) # It's a good practice to use a sleep to make repeated calls to the server
finviz_url <- glue::glue("https://finviz.com/quote.ashx?t={symbol}")
finviz_html <- tryCatch(rvest::read_html(finviz_url), error=function(e) NULL)
if(is.null(finviz_html)) return(NULL)
sector_str %
rvest::html_element(xpath = '/html/body/div[4]/div/table[1]') %>%
rvest::html_table() %>%
head(1) %>%
pull(X4)
sector_df %
str_split("[|]", simplify = T) %>%
str_squish() %>%
as_tibble() %>%
mutate(variable = c("sector", "industry", "country")) %>%
relocate(variable) %>%
add_row(variable = "ticker", value = symbol, .before = 1)
raw_tbl %
rvest::html_element(xpath = '/html/body/div[4]/div/table[2]') %>%
rvest::html_table()
headers % select(seq(1,11,2)) %>% flatten_chr()
values % select(seq(2,12,2)) %>% flatten_chr()
finviz_df %
bind_cols(variable = headers, .) %>%
bind_rows(sector_df, .)
return(finviz_df)
}
And there you have it! A functional scraper in less than 30 lines of code where we showed how to use the convenient library rvest to download financial data from any public company. If you are interested in using R to work with financial data, check out this series we are working on.
#mc_embed_signup{background:#fff; clear:left; font:14px Helvetica,Arial,sans-serif; width:100%;}
#mc_embed_signup .button {
background-color: #0294A5; /* Green */
color: white;
transition-duration: 0.4s;
}
#mc_embed_signup .button:hover {
background-color: #379392 !important;
}
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you’re looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Continue reading: Scraping financial data from finviz with R and rvest package